- Published on
[Cloudflare] D1 사용법
- Authors

- Name
- Almer Minified
[Cloudflare] D1 사용법
클라우드플레어의 D1 이란?
Cloudflare의 D1은 서버리스 데이터베이스이다. AWS에서는 서버리스 데이터베이스가 그냥 켜놓기만해도 한 달에 5만원 이상 나가는데 여기는 굉장히 저렴하다. 소규모 프로젝트에선 안성맞춤이다. 블로그나 간단한 토이프로젝트에 아주 적합한데도 웬만한 기능은 다 구현할 수도 있다. Cloudflare답게 빠른 응답 시간과 스케일 업다운을 신경쓰지 않아도 되는 게 큰 매력이었다. 기본적으로 SQLite를 사용하니 쿼리문도 SQLite를 사용해본 사람이라면 익숙하게 적응할 수 있다.
문서의 부재
근데 대부분 클라우드플레어에 관한 국내 문서가 그렇듯이 D1에 대해 설명해놓은 문서는 많지 않았다. 구글에 검색하니 거의 전무했다. 그래서 내가 쓰려고 한다.
그러나 많은 부분은 공식 문서의 튜토리얼을 따라하며 진행할 것이다. 공식 문서는 자바스크립트랑 타입스크립트랑 두 가지 모두 제공하니 원한다면 공식 홈페이지에서 확인하자.
공식 문서 보기준비사항 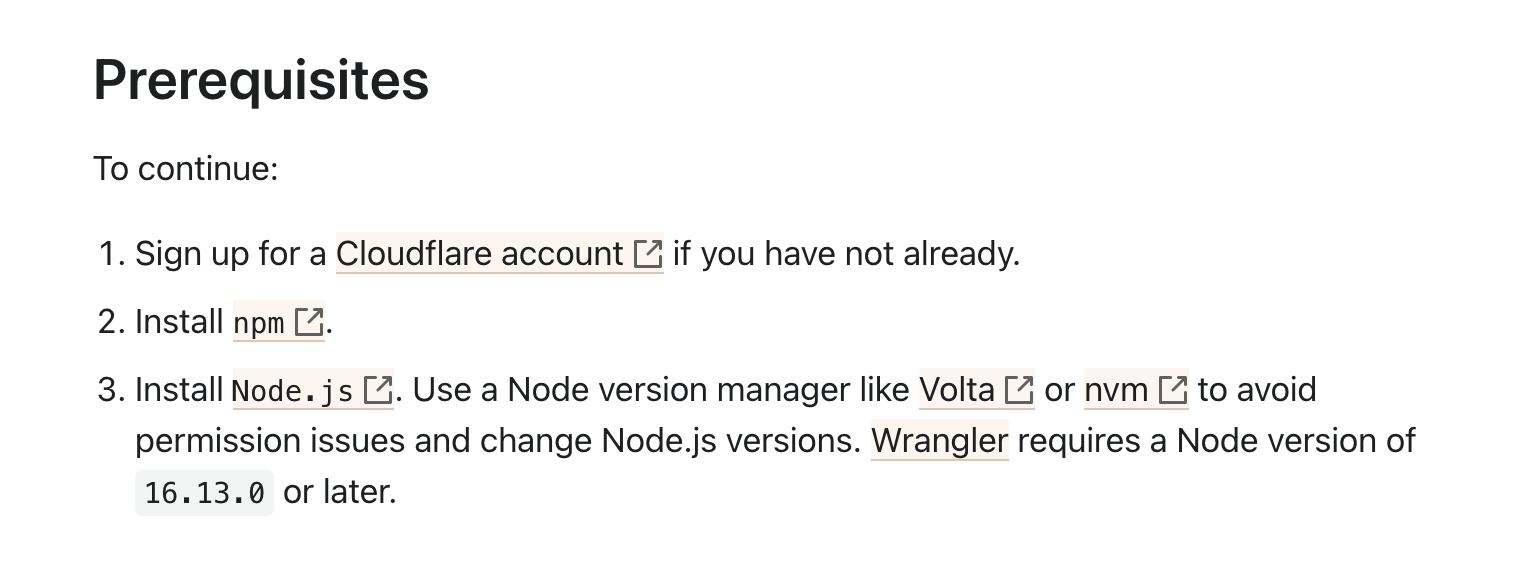 준비물로는 1. 우선 클라우드플레어에 가입되어 있어야 하고 2. npm이
준비물로는 1. 우선 클라우드플레어에 가입되어 있어야 하고 2. npm이
깔려있어야 하며 3. 노드 16.13.0 이상의 버전이 있어야한다. wrangler를 사용하게 될텐데 이걸 위해서 버전을 잘 살펴야한다 요즘은 웬만하면 20대 버전으로 깔리니 걱정하지 않아도 좋을 것이다.
1. 로그인
wrangler에 로그인하자.
npx wrangler login
로그인하게 되면 자동으로 여러가지 선택사항이 뜨는데 브라우저와 연동해서 로그인이 진행되니 클라우드플레어 계정만 있으면 된다.
2. Cloudflare Worker 생성
AWS와 다른 점이 이 부분이다. AWS에서 RDS의 엔드포인트가 주어져서 그걸 바탕으로 직접 쿼리를 날려서 사용하면 된다. 그러나 D1은 그렇지 않고 D1과 연결된 Worker를 생성해서 그 Worker를 통해 쿼리를 보내야한다. 다르게 표현하면 Worker만이 ORM 혹은 웹서버 역할을 해줄 수 있는 것이다. 이 부분이 나도 헷갈렸는데 그렇다고해서 Worker를 통한 엔드포인트, ORM역할 생성이 어렵진 않으니 진행하면 이해될 것이다.
본격적으로 Worker를 생성해보자. 명령어는 다음과 같다
npm create cloudflare@latest d1-tutorial
이 명령어를 쓰면 d1-tutorial 이라는 이름으로 디렉토리가 생성된다. 디렉토리가 생성된다는 것은 로컬에 디렉토리가 생성된다는 뜻이다. 생성한 후의 선택지는 사진으로 첨부한다.
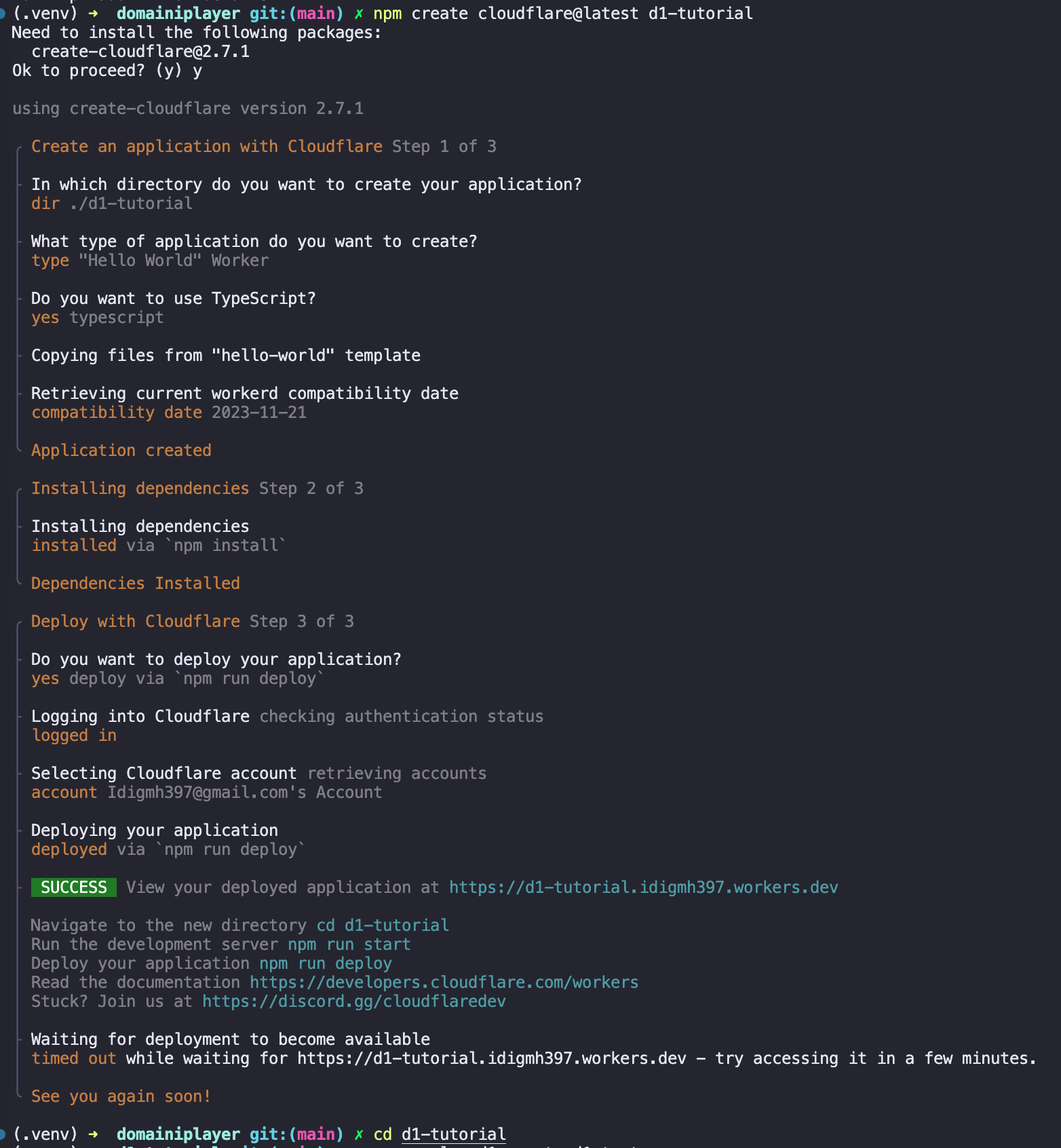 사진을 보면 알다시피 type을 결정할때 Hello World Worker를 선택해야 한다. 그 이후 타입스크립트를 선택하는 것은 본인의 선택이다. 이번 튜토리얼에서는 타입스크립트로 진행할 것이다.
사진을 보면 알다시피 type을 결정할때 Hello World Worker를 선택해야 한다. 그 이후 타입스크립트를 선택하는 것은 본인의 선택이다. 이번 튜토리얼에서는 타입스크립트로 진행할 것이다.한 가지 유의해야 할 것은 이 과정이 끝나고 DNS Propagation 을 기다리는 시간이 좀 길다. 나의 경우는 5분이 넘어갔던 것 같은데 계속 기다리다보면 타임아웃이 뜨지만 별 문제없이 잘 진행된다.
그 다음에 아까 생성한 d1-tutorial 폴더를 보면 wrangler.toml 파일과 src/index.ts 파일이 보일 것이다. 여기서 wrangler.toml파일은 worker의 환경설정을 위한 파일이고 index.ts 파일은 worker가 들어온 요청을 어떻게 처리할 것인지를 정의한다.
3. Database 생성
이제 데이터베이스를 만들자. 지금까지 한 것은 데이터베이스를 만들기 위한 준비작업이다. 서두에서 말했듯 worker가 있어야 D1을 다룰 수 있다. 방금 만든 d1-tutorial 폴더로 이동하자.
cd d1-tutorial
그 다음엔 데이터베이스를 wrangler를 통해 만들 것이다.
npx wrangler d1 create 데이터베이스명
이 명령어 구조에 맞게 만들면 데이터베이스가 생성되고 이런 메시지가 나온다
npx wrangler d1 create DATABASE_NAME
✅ Successfully created DB 'DATABASE_NAME'
[[d1_databases]]
binding = "DB"
database_name = "DATABASE_NAME"
database_id = "unique-ID-for-your-database"
이 메시지의 하단부에 나오는 부분은 바로 toml파일의 하단부에 복사 붙여넣기 해주면 된다.
4. D1 바인딩
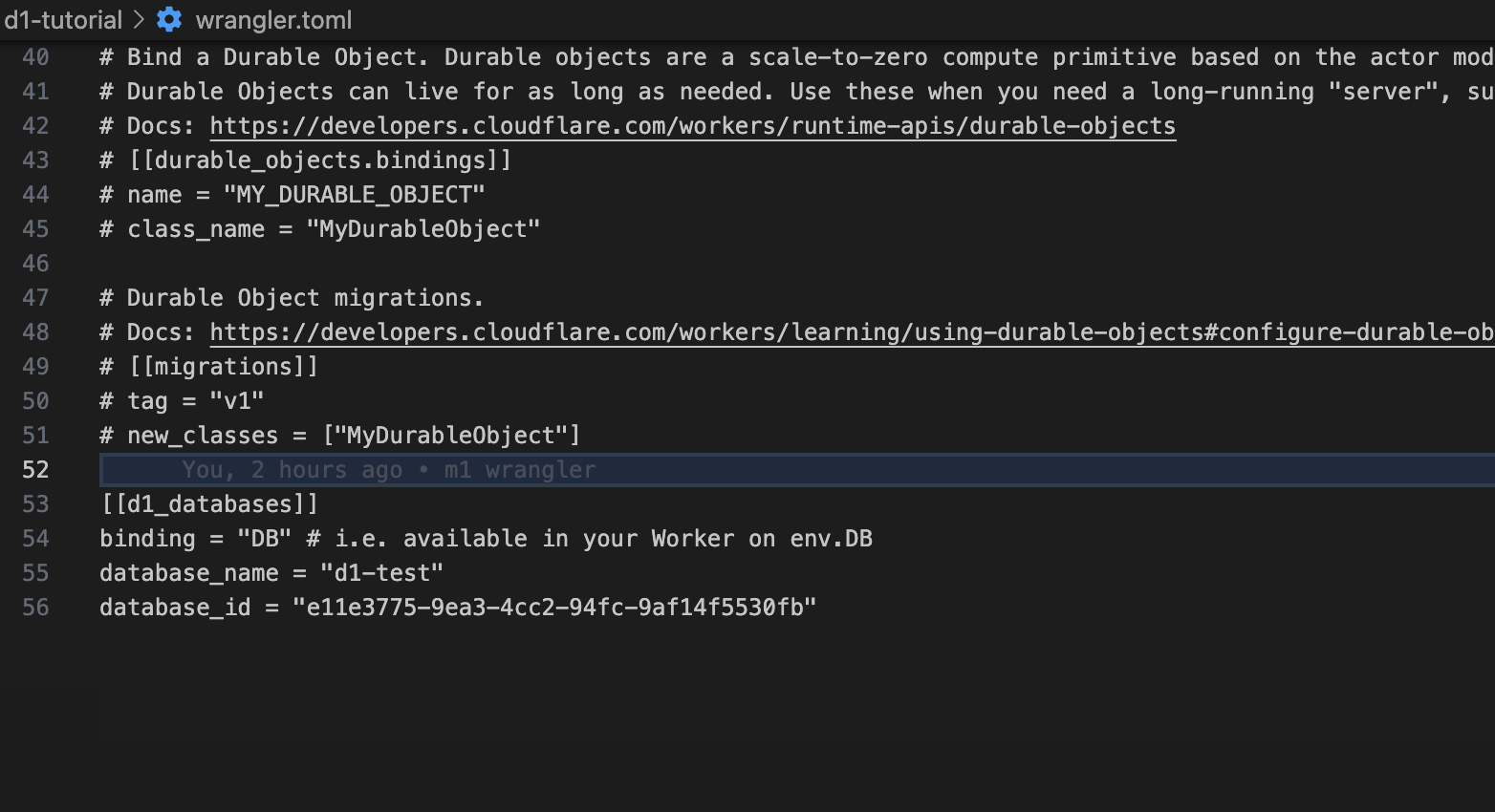 이제 이렇게하면 바인딩이 완료됐다 바인딩 각 의미를 살펴보면 binding="DB" 라고 나온 부분은 나중에 env의 속성으로 DB인스턴스를 가져오는 역할이라고 생각하면 된다. 나머지는 식별자의 역할을 한다
이제 이렇게하면 바인딩이 완료됐다 바인딩 각 의미를 살펴보면 binding="DB" 라고 나온 부분은 나중에 env의 속성으로 DB인스턴스를 가져오는 역할이라고 생각하면 된다. 나머지는 식별자의 역할을 한다바인딩 에서 DB라고 정해진 부분을 원하는대로 수정해도 괜찮다. 여러 DB를 바인딩하게 될 경우 원하는 대로 이름을 설정하면 될 것이다.
5. 쿼리 날려보기
이제 세팅은 다 끝났다. cloudflare에선 친절하게도 로컬에서 실험할 수 있게 해준다. 그야말로 가상의 state를 만들어서 database가 로컬에 있는 것처럼 실험할 수 있게 해준다. 편리한 기능이다. 그 전에 SQL쿼리를 날려서 테이블과 데이터를 만들어보자
DROP TABLE IF EXISTS Customers;
CREATE TABLE IF NOT EXISTS Customers (CustomerId INTEGER PRIMARY KEY, CompanyName TEXT, ContactName TEXT);
INSERT INTO Customers (CustomerID, CompanyName, ContactName) VALUES (1, 'Alfreds Futterkiste', 'Maria Anders'), (4, 'Around the Horn', 'Thomas Hardy'), (11, 'Bs Beverages', 'Victoria Ashworth'), (13, 'Bs Beverages', 'Random Name');
위 코드를 프로젝트 내에 schema.sql이라는 폴더에 생성하자. 이건 쿼리문을 날리기 쉽게 해주는 것으로 만들어놓으면 그 파일명만 입력해주면 쿼리가 되므로 효율적이다
npx wrangler d1 execute <DATABASE_NAME> --local --file=./schema.sql
이제 이 명령어를 쓰면 로컬에서 schema.sql 파일에 있는 명령어를 통해 마치 데이터베이스가 있는 것처럼 만들어준다.
npx wrangler d1 execute <DATABASE_NAME> --local --command="SELECT * FROM Customers"
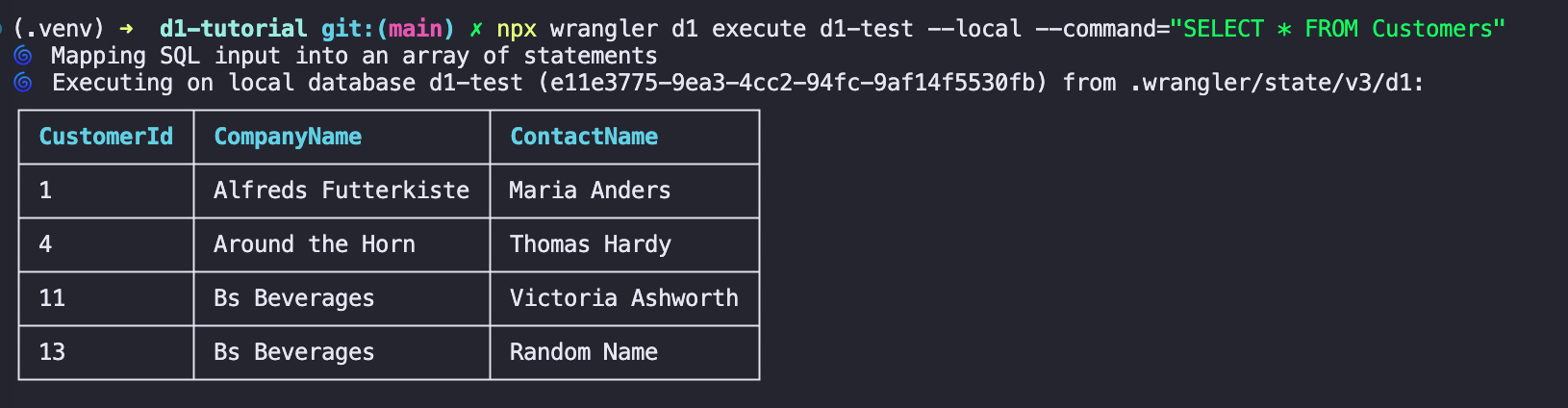
이제 데이터가 잘 들어가있음을 확인할 수 있다.
6. index.ts의 Worker로 DB접근
그 다음엔 index.ts를 조정하여 어떻게 데이터베이스에 Worker내에서 접근할 수 있는지 살펴보자
export interface Env {
// 바인딩 네임을 키로 설정해야 하는 것을 확인하자.
// 물론 아까 이름을 바꿔놨다면 그 이름을 사용하도록 한다.
DB: D1Database;
}
export default {
async fetch(request: Request, env: Env) {
const { pathname } = new URL(request.url);
if (pathname === "/api/beverages") {
// 여기서 아까 결정한 바인딩 네임을 사용한다
const { results } = await env.DB.prepare(
"SELECT * FROM Customers WHERE CompanyName = ?"
)
.bind("야채")
.all();
return Response.json(results);
}
return new Response(
"/api/beverages 를 통해 데이터를 확인하시오"
);
},
};
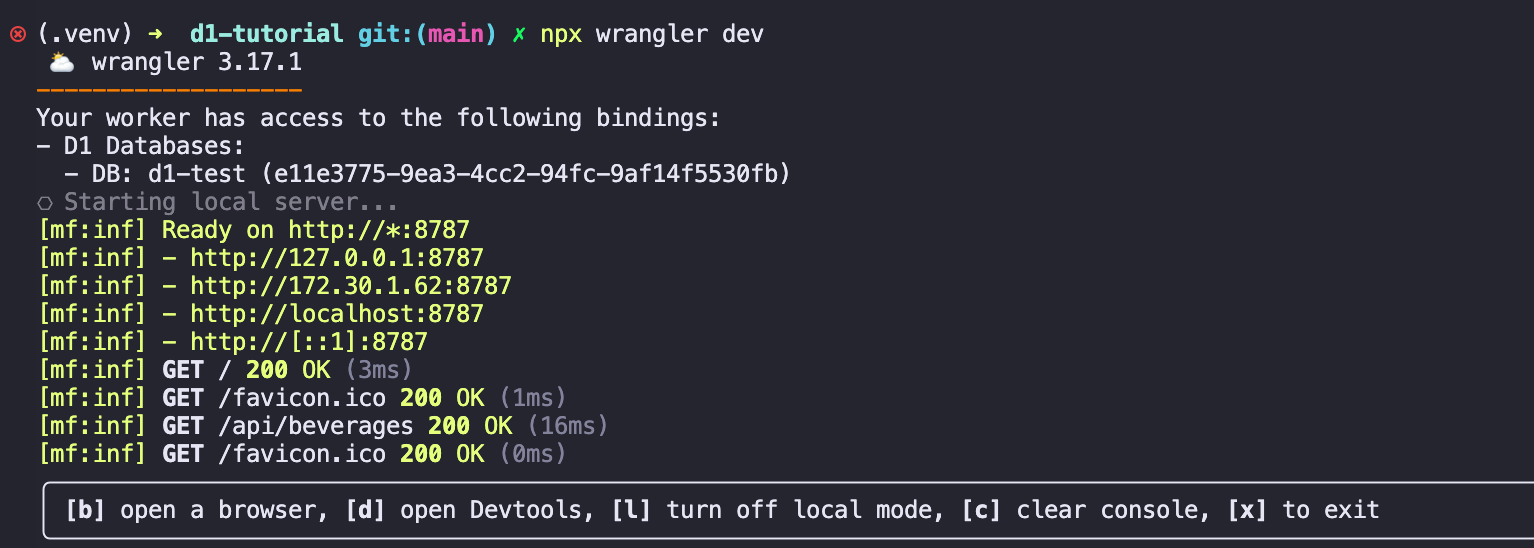
이 명령어는 GET 요청이던 POST던 둘 다 가능하므로 브라우저에서 간단히 쳐보자. 우선 서버를 열어야 하는데 다음과 같은 명령어를 써라
npx wrangler dev
본 서버에 배포
자, 이제 로컬에서 만든 내용을 그대로 서버로 옮겨주면 된다. 명령어 역시 간단하다. 우선 데이터베이스부터 원격으로 마이그레이팅하자
npx wrangler d1 execute <DATABASE_NAME> --file=./schema.sql
npx wrangler d1 execute <DATABASE_NAME> --command="SELECT * FROM Customers"
아까의 명령어에 --local만 빼준 것이다.
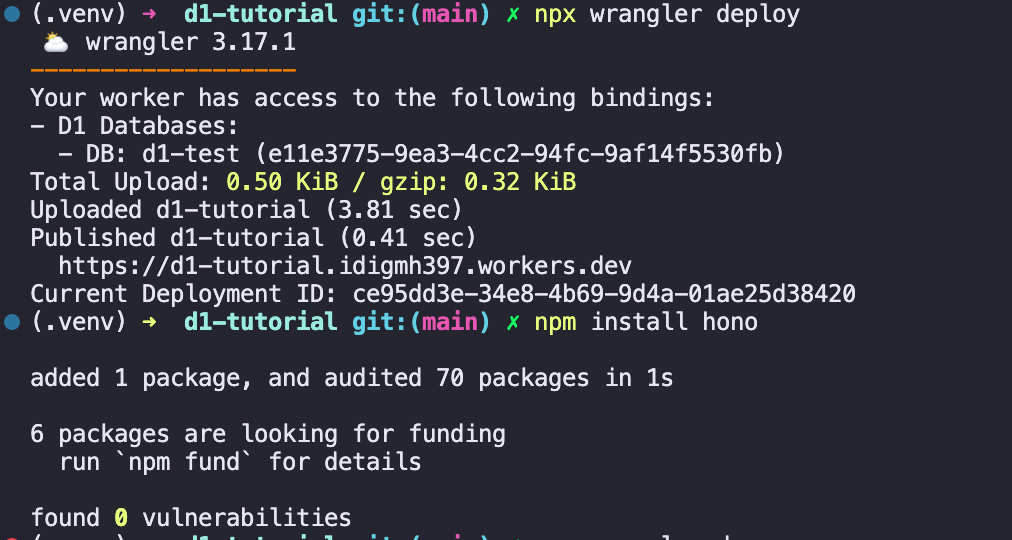
npx wrangler deploy
이제 배포가 완료되었다.
기타 설정
배포가 다 되었으니 클라우드플레어 대시화면으로 가면 이제 Worker에서 원하는 설정을 할 수도 있다. 커스텀 도메인을 입혀서 사용하는 것이 무방하다.